Training a Neural Network using Automatic Differentiation in C++
October 9, 2024In the previous post, we implemented automatic differentiation with computational graphs. Let's now implement a neural network that will learn to memorize a mathematical function.
Prerequisites
This is a follow-up to my previous post on automatic differentiation, you should have read it in order to understand the implementation. This post also assumes you are familiar with neural networks and C++.
The implementation
Layers
The Layer class will be a pure virtual interface that defines two methods:
- forward: will compute the result
- update_weights: will update the weights after the gradient has been calculated
#pragma once
#include "matrix.hpp"
#include <functional>
#include <random>
template<typename T>
using Activation = std::function<Matrix<T>(const Matrix<T>&)>;
template<typename T>
class Layer
{
public:
Layer() = default;
Layer(const Activation<T>& a) : activation(a) {}
virtual Matrix<T> forward(const Matrix<T>& input) = 0;
virtual void update_weights(T lr) = 0;
Activation<T> activation;
};
The Dense class implements a fully connected layer that inherits the Layer interface.
/* ... */
template<typename T>
class Dense: public Layer<T>
{
public:
Dense(size_t n_inputs, size_t n_outputs, const Activation<T>& a = [] (const Matrix<T>& z) { return z; })
: Layer<T>(a)
{
// uniform Glorot initialization
const double r = sqrt(6. / (n_inputs + n_outputs));
std::random_device rd;
std::mt19937 gen(rd());
std::uniform_real_distribution<double> dis(-r, r);
W = Matrix<double>(Eigen::MatrixX<T>::NullaryExpr(n_inputs, n_outputs, [&](){return dis(gen);}));
b = Matrix<double>(Eigen::MatrixX<T>::Constant(1, n_outputs, 0));
W.set_requires_gradient();
b.set_requires_gradient();
}
Matrix<T> forward(const Matrix<T>& input) override
{
return this->activation(input * W + b);
}
void update_weights(T lr) override
{
W = Matrix<double>(W.eigen() - lr * W.gradient());
b = Matrix<double>(b.eigen() - lr * b.gradient());
W.set_requires_gradient();
b.set_requires_gradient();
}
Matrix<T> W;
Matrix<T> b;
};
The weights are initialized using the Glorot initialization technique. We need to call the set_requires_gradient method in order to accumulate the gradient in the backward phase.
In the update_weights method, we assign a new matrix to each weight. While the weight update implementation is simple, it could be optimized to reduce unnecessary creations and deletion of shared pointers.
The Network
To manage our layers, we implement a Network class that will store a vector of unique pointers to its layers.
#pragma once
#include <vector>
#include <memory>
#include "layer.hpp"
template<typename T>
class Network
{
public:
void add_layer(std::unique_ptr<Layer<T>>&& l)
{
layers.push_back(std::move(l));
}
Matrix<T> forward(const Matrix<T>& input)
{
Matrix<T> output = input;
for (const auto& l : layers) {
output = l->forward(output);
}
return output;
}
std::vector<Matrix<T>> predict(const std::vector<Matrix<T>>& inputs)
{
std::vector<Matrix<T>> outputs;
for (const Matrix<T>& input : inputs) {
outputs.push_back(forward(input));
}
return outputs;
}
void update_weights(T lr) const
{
for (const auto& l : layers) {
l->update_weights(lr);
}
}
std::vector<std::unique_ptr<Layer<T>>> layers;
};
The forward method computes the result. Note that matrix assignments only copy shared pointers, not the underlying data.
Training the network
Dataset Generation
First, let's generate our training data using Python:
import matplotlib.pyplot as plt
import numpy as np
plt.style.use('dark_background')
l = np.linspace(-1, 1, 50)
real_grid, imag_grid = np.meshgrid(l, l)
complex_grid = real_grid + imag_grid * 1j
r = np.abs(complex_grid)
theta = np.angle(complex_grid)
z = np.sin(4 * (r + theta))
# saves the figure to a flat sequence of float64
z.tofile('./figure.bin')
# changes the appearance of the figure
plt.figure()
plt.imshow(z, cmap='magma')
plt.xticks([])
plt.yticks([])
plt.colorbar()
plt.show()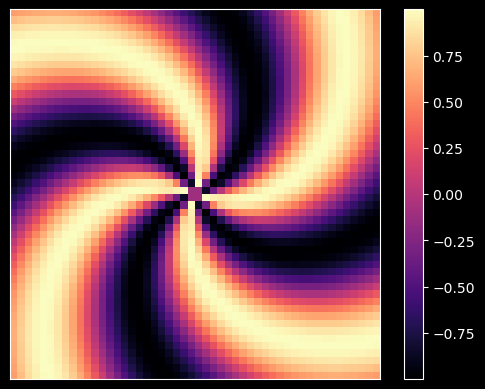
This code generates a whirlpool-like function that will be challenging for the network to learn. Let's break down the steps:
- Creating a grid of complex number grid spanning from \(-1\) to \(1\) on the real axis and from \(-i\) to \(i\) on the imaginary axis.
- Extracting the norm and the argument of each coordinate in our grid.
- Computing \(\sin(4(\theta+r))\)
You can think of the third operation as the height of a sine wave that depends only on \(theta\) around a circle of constant radius \(r\). The sine wave is then shifted as \(r\) increases. We multiply by \(4\) to create a pattern of four minima and maxima on circles of different values of \(r\).
The training loop
We created a file called 'figure.bin' in the 'data' subfolder. The following program parses this file:
#include <fstream>
#include <iostream>
#include <vector>
#include <filesystem>
#include "matrix.hpp"
#include "network.hpp"
// linearly spaced values in the range -1 to 1 with n elements
double linspace(size_t i, size_t n)
{
return -1. + (2. / (n - 1)) * i;
}
int main()
{
size_t nbytes = std::filesystem::file_size(std::filesystem::relative("../data/figure.bin"));
size_t n = sqrt(nbytes / sizeof(double));
if (nbytes % sizeof(double) != 0 || n * n * sizeof(double) != nbytes) {
throw std::runtime_error{ "Invalid figure file" };
}
std::ifstream figure_stream("../data/figure.bin", std::ios_base::binary);
std::ofstream predictions_stream("../data/predictions.bin", std::ios_base::binary);
std::vector<Matrix<double>> x;
std::vector<Matrix<double>> y;
for (size_t i = 0; i < n; ++i) {
for (size_t j = 0; j < n; ++j) {
double val;
figure_stream.read(reinterpret_cast<char*>(&val), sizeof(double));
x.push_back(Matrix<double>{{linspace(i, n), linspace(j, n)}});
y.push_back(Matrix<double>{{val}});
}
}
}The predictions_stream will receive the predictions of our model during its training. The x vector represents the grid we used in Python, but this time not with complex numbers but with row vectors as the coordinates.
int main()
{
/* ... */
Network<double> model;
const Activation<double> relu = [](const Matrix<double>& z) { return z.cwise_max(); };
model.add_layer(std::make_unique<Dense<double>>(2, 16, relu));
model.add_layer(std::make_unique<Dense<double>>(16, 16, relu));
model.add_layer(std::make_unique<Dense<double>>(16, 16, relu));
model.add_layer(std::make_unique<Dense<double>>(16, 16, relu));
model.add_layer(std::make_unique<Dense<double>>(16, 1));
const double lr = 0.001;
const size_t epochs = 1000;
const size_t n_samples = x.size();
}We construct the model with its settings.
int main()
{
/* ... */
for (size_t e = 0; e < epochs; ++e) {
double loss_acc = 0;
for (size_t i = 0; i < n_samples; ++i) {
Matrix<double> output = model.forward(x[i]);
Matrix<double> loss = (output - y[i]).norm();
loss.backward();
model.update_weights(lr);
loss_acc += loss(0, 0);
std::cout << "\rEpoch: " << e << " Loss: " << loss_acc / (i + 1);
}
std::vector<Matrix<double>> prediction = model.predict(x);
for (const Matrix<double>& pred : prediction) {
predictions_stream.write(reinterpret_cast<const char*>(&pred(0, 0)), sizeof(double));
}
std::cout << '\n';
}
}We use loss_acc to accumulate the value of the loss, its purpose is just for debugging.
At the end of every epoch, we send the predictions of our model to the predictions_stream, which will be used later to create a visualization.
Visualizing the training process
To visualize our model's learning progress, we can create an animation using this Python script:
import matplotlib.animation as animation
fig = plt.figure()
# Create axes
ax1 = plt.subplot(121)
ax2 = plt.subplot(122)
# Load data
preds = np.fromfile('./predictions.bin').reshape(-1, 50, 50)
frames = [[ax1.imshow(pred, animated=True, cmap='magma', aspect='equal')] for pred in preds]
for ax in [ax1, ax2]:
ax.set_xticks([])
ax.set_yticks([])
# An animation of 4000ms
ani = animation.ArtistAnimation(fig, frames, interval=4000 / preds.shape[0])
ax2.imshow(z, cmap='magma', aspect='equal')
ani.save("./visualization.mp4", dpi=100, writer='ffmpeg')
plt.close()
This visualization shows the network's predictions evolving alongside the target function, providing a visual insight into the learning process.
Conclusion
We've demonstrated how to combine automatic differentiation with neural networks to create a network capable of learning patterns. The resulting implementation, while straightforward, shows the power of automatic differentiation in building neural networks from scratch.